
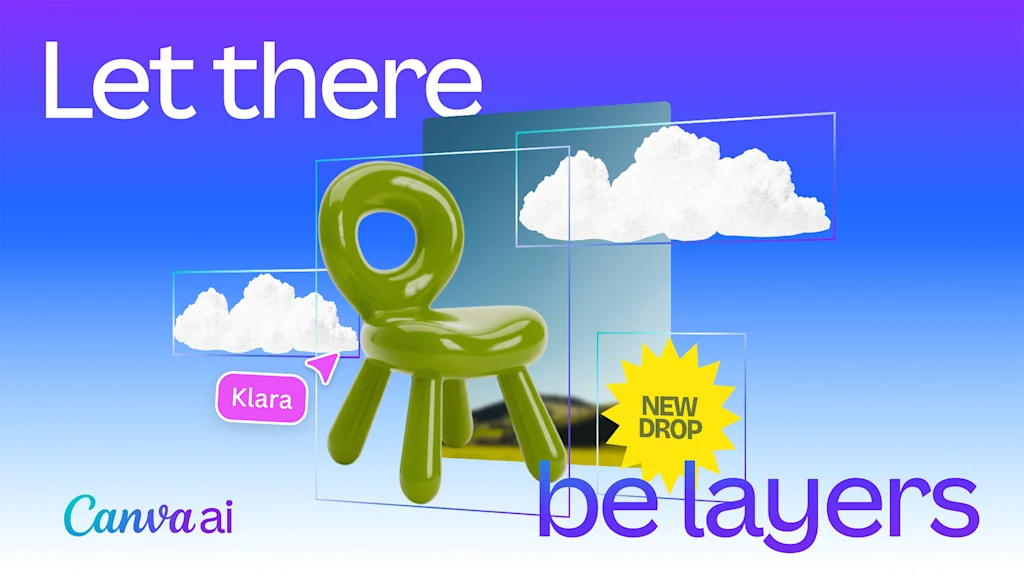
Canva’s new AI tool, launching today, is going to save time, money, and headaches for so many people. Called Magic Layers, it turns any flat bitmap image into a fully editable Canva project, extracting text, objects, and components into individual layers.
This tool marks a fundamental shift in how we handle digital assets. Until now, a rendered image was basically a locked vault of pixels. If you wanted to change a typo or swap a background, you had four options: 1) Hunt down the original project file, 2) painstakingly change it in Photoshop, 3) accept a generative AI patch job, or 4) close the laptop and escape to live a real life somewhere by a nice beach.
Magic Layers shatters the vault. By reverse-engineering a flat picture into its constituent parts, Canva cofounder and Chief Product Officer Cameron Adams tells me, Magic Layers empowers users to resurrect and tweak any image they have on their hard drive.
Canva uses many models from OpenAI, Anthropic, and other developers, but the secret sauce behind this new layering capability is its proprietary AI design model, which the company unveiled last October. Think of it not just as a random design and image generator, but as a model that understands the elements of design.
It looks at a picture and sees its skeletal structure—distinguishing the foreground subjects from the background scenery, and recognizing typography as actual text rather than just colored shapes. When you feed it an image, whether it was spat out by an AI prompt or dragged from an old folder, it dissects those elements perfectly. The new Canva multilayer tool is the implementation of those abilities.
“Most AI outputs are fixed, really flat things, and they’re not easy to edit. You either have to, like, live with an 80% solution or you have to spend time reprompting, trying to get that little bit of the image that you wanted to get fixed,” Adams says. But now, he adds, “the model identifies everything in the frame and converts it into native Canva objects.”
So text isn’t just a cutout anymore. It becomes a live, editable text box. You can correct spelling errors, swap the font, adjust the size, or even translate the copy for international markets. The same goes for visual objects. Once separated, elements like a product bottle or a butterfly become completely independent actors on the canvas. You can move them, resize them, change their color, or banish them from the composition entirely without leaving a gaping hole behind, Adams explains.
And since these extracted layers are treated exactly like standard Canva design elements, you can apply all of the platform’s existing tools to them, including upscaling or generative tweaks like Magic Edit.
“That’s the beauty of it, that it’s now a proper Canva design. So you can change any of those elements in any way,” Adams says. Because Canva operates in the cloud, this newly resurrected file is immediately ready for multiplayer collaboration. You and your team can jump into the project simultaneously and start moving things around.
It’s getting better all the time
There is an interesting parallel here with Adobe’s recent launch of a new AI assistant for its web and mobile Photoshop apps. Both companies are trying to fix the fundamental flaw of current generative AI models like Google’s Nano Banana.
When you ask a standard AI to remove a single item from a picture, the machine recalculates the whole picture from scratch, inevitably introducing random errors or “hallucinations.” Adobe tackles this problem by allowing users to point at or draw around an object. The AI then places these modifications on independent, clear overlays suspended above the base image, preserving the underlying raw pixels flawlessly.
While Adobe’s method builds new, highly controlled edits—including text—on top of an existing foundation to guarantee precision, Canva’s Magic Layers takes the opposite route: It dismantles the foundation itself, breaking the flat image apart into discrete, fully interactive components.
While these tools from both companies do, indeed, appear to be magical, to me they feel like features that are not going to stick around for too long. They’re more like patches that solve generative AI’s current problems with output uncertainty.
Once engines like Nano Banana or Seedream can nail down every pixel, every text and typography, every single human, animal, tree, pair of jeans, or shampoo bottle ever—and it will happen—we will no longer be worrying about things being in layers. Objects, type, and components will simply exist in the reality of the image; the models will understand them just like humans do, allowing users to change anything they want instantly, and with precision.
Everything will be “liquid” for you to touch and change. Software will follow your exacting and most complicated whims with perfection. But for now, Magic Layers is going to solve a lot of problems for a lot of people and companies all around the world.