
Have you ever wondered how ChatGPT can retrieve accurate information instead of making things up (most of the time)? Or how modern search engines understand what you’re looking for even when you don’t use the exact keywords? The magic behind these capabilities lies in embeddings – the invisible architecture that’s currently behind many AI applications through semantic search and Retrieval-Augmented Generation (RAG) pipelines.
As someone who’s been studying embedding-based systems/models in the past months, I’ve seen firsthand how they’ve become the cornerstone of today’s most important AI trends (and increasingly common in job posts). Embeddings are the essential technology powering vector databases, semantic search, and RAG systems that make large language models more factual and contextually aware.
In this Best Courses Guide, I’ve sifted through hundreds of resources to bring you the most effective ways to learn about embeddings with a focus on their practical applications in vector search and RAG pipelines.
Click on the shortcuts for more details:
- Top Picks
- What are Embeddings?
- Courses Overview
- Why You Should Trust Us
- How We Made Our Picks and Tested Them
Top Picks
Click to skip to the course details:


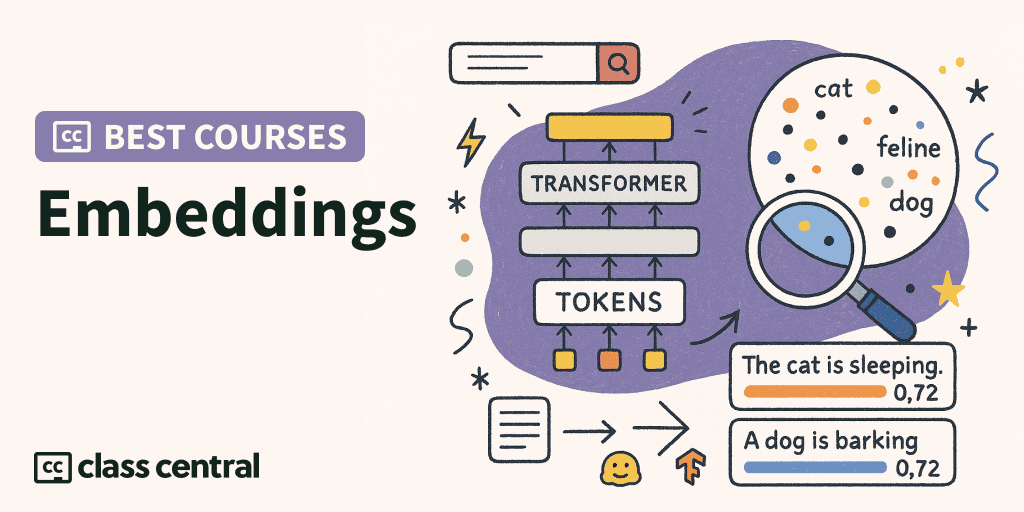
What are Embeddings?
Embeddings are mathematical representations that transform unstructured data like text, images, or audio into dense numerical vectors in a multidimensional space. When you create an embedding, you’re essentially mapping concepts into coordinates where semantic similarity becomes measurable as distance. This capability is why embeddings have become the critical foundation for modern AI retrieval systems.
Embeddings serve three crucial functions:
- Converting Meaning to Mathematics: They translate the meaning of content (documents, queries, images) into a format machines can process, where similar concepts cluster together in the vector space.
- Enabling Semantic Search: Unlike keyword matching such as what you get with Elasticsearch, embedding-based search understands the intent and context of queries, finding relevant results even when keywords don’t match.
- Powering RAG Systems: Retrieval-Augmented Generation (RAG) relies on embeddings to find relevant information that grounds LLM responses in factual data, reducing hallucinations and improving accuracy.
This mathematical representation is the critical link that allows AI systems to locate and retrieve contextually relevant information from vast knowledge bases. In vector databases, embeddings are indexed for efficient similarity search, forming the backbone of systems that can search through millions of documents in milliseconds to find semantically relevant information.
Courses Overview
- 8 courses are free or free-to-audit, while 2 are paid
- Our selection balances application-focused courses (7) with foundational/academic options (3)
- DeepLearning.AI leads with 3 specialized courses focused on practical applications
Best Academic Course on Embeddings and NLP (Stanford)

Stanford’s CS224N: Natural Language Processing with Deep Learning taught by Professor Christopher Manning offers the gold standard in academic treatment of embeddings and their role in modern NLP. This university course provides both theoretical depth and practical implementation skills that serious AI devs need to master.
What distinguishes this course is its academic rigor combined with real-world relevance. Manning is a leading figure in NLP research, and the course systematically builds understanding from word vectors through to transformer models and contextualized embeddings. While application-focused courses may teach you how to use embeddings, CS224N explains why they work the way they do, providing the foundation for understanding transformer models.
This course requires knowledge of Python but programming experience in a different language will also be fine. Some lectures will be using Calculus, Linear Algebra, Statistics and Foundations of Machine Learning.
In this course, you’ll learn:
- The mathematical foundations and theory behind word embeddings (Word2Vec, GloVe)
- How different embedding architectures capture different semantic properties
- The progression from static to contextualized/transformer embeddings (ELMo, BERT)
- Advanced tokenization strategies (BPE, WordPiece, SentencePiece) that affect embedding quality
- Mathematical understanding of embedding spaces and their properties
- Implementing and training your own embedding models with PyTorch
While more demanding than application-focused tutorials, this course provides the foundations needed for more advanced work. The combination of theory and programming assignments makes it ideal for those who want to innovate in this space, not just apply existing models and techniques.
| Provider | YouTube |
| University | Stanford |
| Instructor | Prof. Christopher Manning |
| Workload | 20 hours |
| Views | 50K |
| Cost | Free (public lectures) |
| Quizzes/Assessment Items | 4 Assignments + Final Project |
| Certificate | None |
Most Comprehensive Course on Embedding Fundamentals with Word2Vec (Coursera/IBM)

IBM’s Gen AI Foundational Models for NLP & Language Understanding on Coursera offers a structured approach to mastering embedding techniques within the broader context of natural language processing.
Unlike more application-focused courses, this IBM offering provides a thorough foundation in how embedding models actually work. You’ll progress from basic one-hot encoding to advanced embedding techniques, with hands-on labs with Jupyter to reinforce your learning through implementation. This deeper understanding of the fundamentals enables you to make better decisions when selecting and tuning embedding models for applications in RAG and semantic search.
A basic understanding of Python is required to follow this course.
In this course, you’ll learn:
- The evolution of text representation from one-hot encoding to modern embeddings
- Implementing Word2Vec models and understanding how they capture semantic relationships
- Building and training neural language models that leverage embeddings
- Applying embeddings for document classification with practical PyTorch implementation
- Techniques for evaluating embedding quality and model performance
- Understanding sequence-to-sequence models that use embeddings as foundational components
| Provider | Coursera |
| Institution | IBM |
| Instructor | Joseph Santarcangelo, Fateme Akbari |
| Workload | 9 hours |
| Enrollments | 9.9K |
| Ratings | 4.4 (108) |
| Cost | Free to audit |
| Quizzes/Assessment Items | Quizzes and labs |
| Certificate | Available, paid |
Also Great Foundation Course for Understanding Embedding Concepts (Calmcode.io)

Calmcode.io’s Embedding Course stands out for its intuitive approach to teaching embedding concepts. Rather than starting with complex mathematics, instructor Vincent D. Warmerdam focuses first on building your intuition through elegant, simplified examples that make the underlying principles clear.
What makes this course special is how it demonstrates how embeddings emerge as a natural byproduct of prediction tasks. Through a clever experiment training letter embeddings to predict subsequent letters, you’ll see firsthand how meaningful patterns naturally organize in vector space—the fundamental principle behind all modern embedding applications. This conceptual foundation is vital for anyone who wants to move beyond just copying code to truly understanding how to optimize embedding-based systems.
In this course, you’ll learn:
- The fundamental intuition behind how embedding spaces organize meaning
- Why similar concepts naturally cluster together in embedding spaces
- How embedding patterns emerge as “side effects” of prediction tasks
- The connection between simple embedding examples and production applications
- Key concepts that apply across text, image, and multimodal embeddings
| Provider | Calmcode.io |
| Instructor | Vincent D. Warmerdam |
| Workload | 2 hours |
| Cost | Free |
| Quizzes/Assessment Items | None |
| Certificate | None |
Best Practical Course for Applying Embeddings to Research Agents (DeepLearning.AI)

Now that you’ve learned how embeddings work, let’s bridge the gap between understanding embeddings theoretically and implementing them in advanced RAG systems that perform multi-step reasoning. Building Agentic RAG with LlamaIndex taught by Jerry Liu, co-founder and CEO of LlamaIndex, shows how to apply embedding techniques to create autonomous research agents.
While Stanford’s CS224N provides the theoretical foundation of embeddings and IBM’s course covers their fundamental implementation, this course demonstrates how to orchestrate these embeddings in production-ready applications. You’ll see how vector representations enable intelligent document routing, metadata filtering, and multi-document analysis.
In this course, you’ll learn:
- Using embeddings to create routing systems that select between Q&A and summarization tools
- Implementing vector search with metadata filters for precise document retrieval
- Building tool-calling capabilities where LLMs leverage embedding spaces to make decisions
- Creating multi-step reasoning agents that navigate embedding spaces across multiple documents
- Practical techniques for debugging and optimizing embedding-powered agents
- How to convert static embeddings into dynamic, goal-oriented research workflows
| Provider | DeepLearning.AI |
| Institution | LlamaIndex |
| Instructor | Jerry Liu (LlamaIndex co-founder/CEO) |
| Workload | 1 hour |
| Cost | Free |
| Quizzes/Assessment Items | Jupyter labs |
| Certificate | None |
Also Great Practical Course for Embeddings with Cohere in Semantic Search Applications (DeepLearning.AI)
Another practical course with an even simpler implementation of embeddings. Large Language Models with Semantic Search provides an introduction to using embeddings specifically for retrieval and semantic search applications.
What makes this course exceptional is its practical, application-focused approach. It shows you how to implement embedding-based search systems using Cohere.
In this course, you’ll learn:
- How to generate embeddings using models for search applications
- Techniques for implementing semantic search with embeddings and similarity metrics
- Creating re-ranking systems to improve search relevance
- Building a complete search pipeline from document processing to retrieval
- Build a simple system to interact with a document that outputs answers instead of search results
| Provider | DeepLearning.AI |
| Institution | Cohere |
| Instructor | Jay Alammar, Luis Serrano |
| Workload | 1 hour |
| Cost | Free |
| Quizzes/Assessment Items | Jupyter labs |
| Certificate | None |
Best Tutorial for Semantic Search with FAISS and Sentence-Transformers (Hugging Face)

Hugging Face’s Semantic search with FAISS tutorial offers a focused, code-first approach to implementing embedding-based search using the popular Hugging Face ecosystem. This free resource demonstrates how to build a functioning semantic search engine using sentence transformers and the FAISS similarity search library.
What makes this tutorial exceptional is its practical, no-nonsense approach with real code examples. Unlike theoretical discussions, this tutorial takes you through the actual implementation steps: loading data with Datasets, generating quality embeddings with sentence-transformers, setting up FAISS for vector indexing, and running similarity searches. The tutorial is refreshingly direct, showing you exactly how to turn embeddings into a working search system.
| Provider | Hugging Face Learn |
| Institution | Hugging Face team |
| Workload | 1-2 hours |
| Cost | Free |
| Quizzes/Assessment Items | Code Examples |
| Certificate | None |
Best Embedding Optimization Course for Production Systems (DeepLearning.AI)

DeepLearning.AI’s Retrieval Optimization: From Tokenization to Vector Quantization, created in partnership with Qdrant, addresses the challenge of making embedding-based retrieval systems performant and efficient enough for production use. Led by Kacper Łukawski, Developer Relations Lead for Qdrant, this course focuses on the often-overlooked optimization aspects that determine whether a system can scale to millions of documents.
What sets this course apart is its focus on the entire optimization chain for embedding-based retrieval – from how tokenization choices affect embedding quality to sophisticated techniques for reducing storage and search time. These optimizations can be the difference between a prototype and a production-ready system that delivers results in milliseconds.
In this course, you’ll learn:
- How tokenization methods (wordpiece, byte-pair encoding, unigram) impact embedding quality and retrieval performance
- Techniques for measuring and improving search relevance using real-world metrics
- Optimization strategies for HNSW graph parameters to balance speed and accuracy
- Vector quantization methods (product, scalar, binary) to dramatically reduce memory usage
- Implementation of these optimizations with practical code examples
- Performance benchmarking and tuning for real-world retrieval applications
| Provider | DeepLearning.AI |
| Institution | Qdrant |
| Instructor | Kacper Łukawski |
| Workload | 1-2 hours |
| Cost | Free |
| Quizzes/Assessment Items | Jupyter labs |
| Certificate | None |
Best Course for Implementing RAG in Google Cloud with BigQuery (Google Cloud)

Create Embeddings, Vector Search, and RAG with BigQuery by Google Cloud Training teaches you how to implement embeddings and RAG within Google’s cloud ecosystem. This course demonstrates how embedding techniques and vector search can be implemented at scale using BigQuery’s powerful data processing capabilities.
What makes this course valuable is its direct application to real-world enterprise environments where BigQuery is already used for data analytics. The course bridges the gap between AI theory and practical implementation at scale, showing how embedding techniques can be integrated into existing data pipelines rather than requiring separate specialized infrastructure. For those working with Google Cloud, this represents the most direct path to production-ready RAG systems.
In this course, you’ll learn:
- Generating embeddings at scale using BigQuery’s integration with foundation models
- Implementing efficient vector search across massive datasets within BigQuery
- Building complete RAG pipelines that leverage Google Cloud’s managed services
- Practical considerations for embedding model selection in cloud environments
- Performance optimization techniques for large-scale vector operations
- Integrating RAG capabilities with existing BigQuery-based data workflows
| Provider | Google Cloud Skills Boost (also on Pluralsight and Coursera) |
| Workload | 2 hours |
| Cost | Free |
| Quizzes/Assessment Items | Module quiz and labs |
| Certificate | Free Badge |
Best Hands-On Course for RAG Development (Udemy)

Udemy’s Basic to Advanced: Retrieval Augmented Generation (RAG) by Yash Thakker offers a hands-on course for building complete Retrieval-Augmented Generation systems powered by embeddings. This project-focused course emphasizes practical implementation over theory, taking you through the entire process of building production-grade RAG applications.
This course focuses on building three fully functional chatbots (Website, SQL, and Multimedia PDF chatbots). The instructor will guide you through setting up real embedding pipelines, configuring vector stores, and implementing advanced retrieval techniques. You’ll work with actual code and real-world data, including the Tesla Motors database for practical exercises.
In this course, you’ll learn:
- End-to-end RAG architecture with embeddings at the core
- Practical implementation of different embedding models and when to use each
- Setting up and optimizing vector databases (FAISS, ANNOY, HNSW methods)
- Advanced retrieval techniques like query expansion and result re-ranking
- Performance optimization for embedding-based retrieval
- Deployment considerations for production RAG systems (AWS EC2)
| Provider | Udemy |
| Instructor | Yash Thakker |
| Workload | 2-3 hours |
| Cost | Paid |
| Rating | 4.8/5 (829) |
| Quizzes/Assessment Items | Code examples |
| Certificate | Available |
Best Hands-On Course for Transformer Implementation (DataCamp)

DataCamp’s Transformer Models with PyTorch offers an interactive approach to mastering transformer embeddings. Led by James Chapman, Data Science & AI Curriculum Manager at DataCamp, this course takes you step-by-step through implementing transformer components and models using PyTorch.
Rather than just explaining transformer concepts, the course has you actually coding the components yourself – from attention mechanisms to complete encoder and decoder structures. This provides deeper insight into how the embedding models that power modern AI applications actually work under the hood.
In this course, you’ll learn:
- Practical implementation of transformer architecture components in PyTorch code
- Building attention mechanisms from scratch, including multi-head attention
- Constructing different transformer variants: encoder-only (BERT), decoder-only (GPT), and encoder-decoder models
- How to adapt transformer architectures for specific NLP tasks (classification, generation, translation)
- Techniques for implementing positional encoding, feed-forward networks, and other key components
- The relationship between transformer architectures and the embeddings they generate
| Provider | DataCamp |
| Instructor | James Chapman |
| Workload | 2 hours |
| Cost | Paid |
| Rating | 4.8 (207) |
| Quizzes/Assessment Items | 23 exercises with interactive platform |
| Certificate | Available |
Why You Should Trust Us
Class Central, as a Tripadvisor for online education, has helped over 100 million learners find their next course. We’ve been combing through online education for more than a decade to aggregate a catalog of over 250,000 online courses and reviews. Our team has collectively completed hundreds of online courses, giving us unique insight into what makes effective educational content across different platforms and teaching styles.
How We Made Our Picks and Tested Them
Finding the “best” embedding courses required a methodical approach that combined objective metrics with qualitative assessment. Here’s how I approached this task:
First, I conducted a learning audit to understand the challenges specific to embedding education. This involved analyzing discussions in specialized forums including r/learnmachinelearning and r/MachineLearning. I also reviewed questions on Stack Overflow and the OpenAI Developer Forum to identify common pain points and knowledge gaps.
Based on this research, I identified key criteria for effective embedding courses:
- Clear explanations of the mathematical concepts without overwhelming beginners
- Visual demonstrations that build intuition about embedding spaces
- Practical implementation examples with modern tools and libraries
- Coverage of optimization techniques for production deployment
- Exploration of ethical considerations such as bias in embeddings
I then compiled an initial selection of over 30 potential resources across various platforms, including MOOCs (Coursera, edX), specialized platforms (DeepLearning.AI, Hugging Face), and other online resources.
For courses I hadn’t personally completed, I watched sample lectures, reviewed syllabi, and consulted community feedback. I paid particular attention to comments that highlighted specific strengths or weaknesses of each resource.
The final selection represents a balance of different learning styles, technical depths, and focus areas to accommodate various learner needs – from visual thinkers who benefit from intuitive explanations to technical practitioners seeking implementation details.
What’s Next After Learning Embeddings?
Mastering embeddings is just the beginning. Here are the next steps to build on your embedding knowledge:
Community Resources
- SentenceTransformers: Various code examples and tutorials to implement computing embeddings, semantic search, paraphrase mining, and more.
- LlamaIndex Documentation: A comprehensive resource for building RAG applications with detailed tutorials on embedding approaches.
- LangChain Tutorials: Valuable examples of integrating embeddings into complete RAG workflows.
- Hugging Face Spaces and Forums: Join the community showcasing embedding applications and discussing implementation challenges.
- GitHub’s Awesome Vector Database: A curated list of vector database options, benchmarks, and implementation guides.
Practical Project Ideas
- Build a document retrieval system for a specialized knowledge domain
- Create a hybrid search application that combines keyword and semantic search
- Implement a RAG-powered chatbot for a specific business knowledge base
- Develop a multimodal search system that can find relevant content across text and images.

The post 10 Best Courses to Master Embeddings and Transformer Models in 2025 appeared first on The Report by Class Central.


